
AI时代,6小时做一款游戏! ——九四玩
数个月前,由MidJourney生成的数字油画在Colorado博览会的艺术比赛中拔得头筹,该事件不仅引发了人们对“AI绘画是否为艺术”的巨大争论,同时也让AI绘画这一黑科技借着舆论的浪潮席卷网络。
![]()
从文本生成图片、图片生成图片,到文本生成3D模型、文本生成短视频,AI工具在海量网民的奇思妙想下,生成了诸多高质量或有趣的内容。在这场技术狂欢里,至少看到了这么几个趋向:
1.技术范式,基于库恩—佩蕾斯对于“范式”概念的阐释与演化,技术的演变伴随着价格结构的重大变化,从而引导经济行为者倾向于使用更强大的新投入品与新技术。之于AI绘画而言,它又可细分为——
技术的渐进式发展与跃迁,AI绘画在近几个月能突飞猛进式源于Diffusion扩散模型在图片生成领域的使用以及Stable Diffusion的开源,但这些跃迁无不建立在技术的长期研究基础上;
市场前景引发技术竞争,AI绘画技术的火热引起了全球巨头、科技公司的高度关注,谷歌、微软、Adobe等公司纷纷推出新的模型与实验性项目,并试图将该项技术整合到自家产品中, Stable Diffusion背后的创业公司融资一亿美元以进行更深入的研发;
AI绘画作为一种生产工具,将催生新的需求、岗位,或是改变现有的生产流程。
![]()
2.公众对绘画或艺术的再一次审视,如同杜尚用现成品艺术颠覆了人们对艺术的认知,计算机生成的图画引发了人们对艺术、人类创造力本质的新的讨论;
3.AI绘画对现有法律、社会认知的冲击,如AI的训练数据以及生成的图像是否对艺术家的作品构成侵权,AI生成图像是否有版权等。
在这些趋向与讨论中,新技术所引起的失业焦虑无疑是最具冲击性的话题之一,它是否会像部分网友所说的,取缔“低端”画手?
![]()
事实上,“取缔”与“低端”都不是贴切的说法,我们可以换个角度去思考AI绘画对美术从业者的潜在影响——将AI绘画产品的出图流程与人类作图的流程以及最终想要得到的成品放在同一个框架内考虑,得出哪些环节、成品可以被AI绘画优化甚至平替的。
基于这一思路,不难想象,约稿市场,可能会成为AI绘画蚕食的重灾区,又或者是那些仅需要数张插画的小说、有声作品等。
之于游戏产品,美术占比重、玩法固定的AVG游戏,同样岌岌可危。
这不,AI绘画热潮刚蔓延至国内的那段日子,就有个团队趁势做了个“由AI制作”的AVG游戏——《未来地狱绘图》。
《未来地狱绘图》
“由AI制作”,这一描述并不准确,《未来地狱绘图》的实质是用AI工具生成大部分游戏资产,如剧本、角色立绘、美术背景等,最后由人工完成素材的组合。
![]()
游戏由拔丝柠檬制作组制作,据官方在B站发布的介绍视频,游戏第一章的制作时长仅仅只有6个小时,游玩时长大概为10分钟左右,全程无对话选项,相当于一个视觉小说。
![]()
目前游戏可在Gamecreator网站在线游玩,更新至第二章节。
![]()
AVG游戏的制作门槛并不高,尤其是纯视觉小说类型的文字冒险游戏,它并不需要嵌入过多的游戏交互行为或游戏系统,市面上也存在着大量用于制作AVG游戏的引擎或平台,如吉里吉里、橙光。理论上,制作者仅需搞定剧本、美术(角色、场景、CG、特效等)、音乐(音乐、音效、配音等)三大模块,就能制作出一款能交互的AVG游戏。
而这三者,均在AI生成内容的范围内。
(1)剧本
《未来地狱绘图》使用的是彩云科技开发的人工智能小说续写工具彩云小梦。
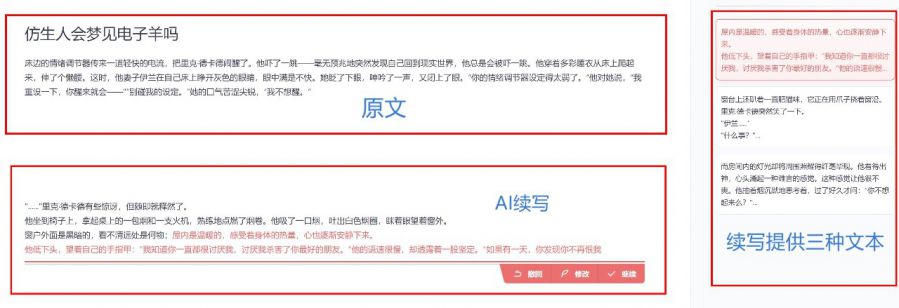
用户在应用界面中输入故事开头、词语或主人公名称后,AI会自动续写下文,用户可以选择续写的风格,如“纯爱”、“玄幻”,也可上传文本训练出自己想要的模型,还能对故事的世界观进行编辑。每次续写时,AI会提供三种文本,不喜欢的话可以换一批。
![]()
该应用在去年曾火过一阵子,在B站上,以「AI续写」为标题的系列视频每一条都有着几十万的播放量,但这一热度并非基于AI续写的故事的质量产生的,纵览AI生成的文本,里头满是硬伤:故事逻辑性弱、语句毛病多,观众更多的是持着一种看乐子的心态,人类的围观与在AI基础上生成的脑洞远比故事本身更加有意思。
从彩云小梦在《未来地狱绘图》中的实际应用来看,行文硬伤依旧存在,语义重复的毛病并不少见:
![]()
但它至少做到了一件事,能够把事情讲清楚了——未来某一年,玩家所扮演的「员工」被AI所淘汰,试图反抗的“我”被教训了一顿后关进了看守所(第一章)。不知过了多久,“我”沦落街头,乞求能找到一份工作,并透露出自己此前的身份——能画出千万美元价值画作的画师。在小巷收废品时“我”遇到一名被遗弃的女仆机器人,“我”萌生了同病相怜的情愫,谁知,这竟是个圈套,性命攸关之际前同事打开了仓房的门(第二章)……
除了故事发生的前后逻辑能理得清外,AI创作的文本还有另一个比较令人意外的点,即每个角色的台词符合其人设。
通读下来,故事给人的感觉就是缺乏相应的铺垫或没有明确的发展方向,转折虽然有出人意料的效果但显得生硬。
(2)音乐
《未来地狱绘图》的AI音乐主要分为两大块,背景乐与角色配音,音效使用的是免费素材。
![]()
计算机领域对音乐的解析远比绘画要早得多,上个世纪50年代便有研究者尝试着用计算机随机生成弦乐。在神经网络技术的辅助下,人工智能已能熟练“掌握”音乐的基本原理并生成有一定表现力的音乐。
![]()
《未来地狱绘图》所使用的AIVA便是AI生成音乐领域的佼佼者之一,它允许玩家对生成的音乐进行编辑。不过,在《未来地狱绘图》里,AI生成的BGM存在感并不强,虽然算是一首能听的曲子,但并不能与当前的文本、画面完全贴合,产生1+1>2的效果。
相比AI生成的音乐,AI配音则要常见得多,公共广播、短视频中等随处可见,在营销号、电影解说中的使用更为泛滥,其中以微软AI语音云希、阿里云的艾飞最为普遍。
虽然这些AI配音已听不出太多机械音的痕迹,但它们只适用于解说等无需情感掺和的场景,在视觉小说这类强调故事性与角色的作品中,声音需要被赋予更多的情绪与灵魂。换言之,它需要更为复杂的语调、音长变化,于是便有了语音合成标注工具。
在《未来地狱绘图》所使用的声咖AI中,用户不仅能选择语音类型、朗读速度跟音量,还能对朗读文本逐字进行标注,通过停顿、强调、连读等方式实现发音的节奏变化。部分AI配音应用,如Uberduck,甚至允许用户自行上传音频素材训练出特定的模型,直接模糊同人与官方的界限。
![]()
不过,在《未来地狱绘图》的具体体验中,AI配音的表现其实很糙,机械感明显是其一,语调与发音人所处情景不吻合是其二——像“带走”、“给我进去”这些带有强迫性意味的词语尾音却拉得很长,既不符合机器人无情感的特性、也不符合人类的情感倾向。
相比AI配音,AI变声器是个更具效率的配音方案,如MockingBird、MoeGoe,后者在二次元领域较为常见,它收录了接近三千名动画角色的声音,可生成中文、日文、英文、韩语等多种语言,目前在日本的Vtuber行业有较高使用率。
(3)美术
回到本文、同时也是《未来地狱绘图》之所以会被做出来的契机上,AI绘画是三类AI生成内容中最具视觉冲击力(虽然它本身就是视觉产品)、成品最接近人类作品的,在媒体、互联网大规模曝光AI绘画技术以及Stable Diffusion开源之后,国内外涌现出了大量新AI绘画产品。
但总体而言,关注焦点依旧集中在DALL-E、Midjourney、Stable Diffusion上。
三者中,DALL-E算得上是奠基者。如今主流的文本生成图像(Text to Image,下文简称T2I)工具使用的模型均为CLIP+Diffusion,前者为计算机能够理解文本与图像之间的对应关系搭建起了桥梁,并网罗互联网中数十亿的图片作为自己的训练数据;后者则是利用“去噪点”的方式实现图像的精细度。DALL-E背后的开发团队Open AI于2021年1月开源了CLIP模型后,为TTI的跃进式发展提供了契机。
Midjourney的成名也许要归功于Colorado博览会上的伟大胜利,由其生成的作品力压人类艺术家拔得头筹,基于训练库的差异,Midjourney生成的图像更强调光影细节与美学观感。
![]()
Stable Diffusion后来居上,它秉承着完全开放的原则,过滤少、没有严格的版权保护机制(即使有,也能被轻易绕过或破解),输出的风格更为广泛,使用更为便捷,生成速度更快,且可得到社区支持。
![]()
当然,《未来地狱绘图》所使用的Novel AI也是AI绘画领域的佼佼者,尤其是在AI生成二次元画像方面。
![]()
运用到具体的AVG游戏制作中,AI所需要做的工作不能只停留于根据提示词生成图像,它至少还需要做到:
保证所有输出图片在风格上的统一性;
为同一角色绘制不同的动作与表情差分;
用于渲染氛围、展现故事张力的CG需要能够与上下文相一致,如角色样貌、服饰、场景等。
需要特别提醒的是,以上需求均建立在无人工改图、AI直出的情况下。
在《未来地狱绘图》中,制作者极力避免同一场景需要两张美术背景(如同一间屋子的不同部位)的情况,对于“场”做了明显的切割,至于角色的表情差分、动作差异,则一概摒除。
在CG如何与立绘保持统一这一关键需求上,游戏同样没能给出一个比较好的解决方案。
![]()
从《未来地狱绘图》的实际表现来看,无论是文本、音乐还是美术,AI生成的游戏内容都未能均不尽人意,也许单个(单张图片或片段性的文字)拎出来看成效还行,但全部拼贴在一起多少有些别扭,就像贫困的村庄里盖了个六七层的高楼,外体砌的砖墙五花八门,或古朴或时尚,或黄或绿,它缔造的不是奇观,而是单纯的不协调。
不过也别忘了,上个世纪的波普艺术便是用拼贴、剪切商品包装的方式成为一种新时尚的,也许AI生成的内容不是取缔现有的作品,而是成为新的一个品类呢?就像观众将AI小说当成乐子而非常规作品一样,媒介的差异造成了认知方式的差异。
但《未来地狱绘图》并不意味着就是AI在游戏创作上的极限,它只不过是个几个小时内鼓捣出来的实验性作品,理论上制作者可以用更好的AI工具、更细致的“调校”来生成更出色的作品,其结果便是——
与使用AI的初衷背道而驰,制作者需要投入更多的时间,甚至是金钱。
![]()
为了更好地理解《未来地狱绘图》以及AI生成内容在游戏制作上的实际使用,找上了游戏背后的开发团队,拔丝柠檬制作组。
一言难尽的AI生成技术
拔丝柠檬制作组的成立时间不足半年,出于了解新技术的态度,他们尝试着用AI工具鼓捣出了《未来地狱绘图》。
第一章花了大约6个小时的时间,因为是抱着做着玩的心态,所以对生成的素材并不细抠,能用即可。
第二章则花了两倍的时间,制作组想尝试用AI做更多的东西,比如CG——让AI生成同一角色的不同图片,制作人NIM表示,“即使是截取大量同角色的图片进行训练,让AI记住角色,生成的图片在细节上的差异也是不可避免的。”
用AI工具创作的《未来地狱绘图》只是拔丝柠檬制作组的试水作品,团队的工作重心在另一款AVG游戏《井域:喀洛之血》。
![]()
基于拥有用两套创作方式(人工与AI)来创作同一类型游戏的经历,拔丝柠檬制作组在“AI绘画是否会对游戏行业造成冲击”这一话题上有着更为真切的感受。
其初步结论是,目前用AI工具来创作AVG游戏并不见得更有效率。
比如文本,“彩云小梦生成的文本没有逻辑,如果想要达到能看的程度,免不了要人的参与”,相比纯试验性的第一章,第二章有了更多人工修改的痕迹,NIM没有直接更改AI的文风,但对生成的原句进行了大量剪辑与重复生成,以确保生成的文本没有过于偏离制作者的构思,但即便是采用这种低成本驯服AI的方式,最终还是花费了大量时间,相比人工撰写来说并不划算。
![]()
比如配音,AI直出的音频没有太多感情,需要进行精确的调参,但在AVG这种文本量动辄几十万起的游戏来说,调校过程中需要倾注的人力未必少于真人配音。
美术方面的问题也不少,第一是同质化明显,Novel AI生成的图相似性高,脸型重复,不适合用于原创的商业作品;第二是它无法满足专业需求,比如高分辨率的立绘,AI生成的图片放大后效果并不理想,又比如图片没有分图层,可供调整的余地不大;第三,CG难以保证角色的一致性;第四,生成的图有不少细节上的问题,这些都需要人工去修复。
![]()
但NIM并未完全否决AI的作用,以上结论建立在两个基本点上,一是目前AI生成工具的水准,二是使用者的用途与标准,如果仅是追求可读、可用的话,目前的AI完全能取代人工产出制作AVG游戏所需要的游戏资产。
对于NIM来说,在AVG游戏创作领域,AI生成工具有个明显的优势:
进一步降低制作门槛,让那些有想法或有故事想要表达的个体作者也能利用AI工具来创作游戏。B站上涌现的同人作品便是一个有力的证据。创作者们以VUP/Vtuber或者是一些现有IP为原型,将角色图片、配音“喂食”给AI,然后根据自身需求生成想要的内容,真正意义上让零美术基础的同学也能进而二创圈。
![]()
拔丝柠檬制作组还在B站上展示了一种利用AI绘画生成2D动画的技巧,先“喂食”图片生成可用的模型,然后用MMD制作3D动画并导出序列帧,最后用AI绘画将其转换成2D动画。
不过,这样生成的动画往往是由一张张重新绘制的图片合成的,一来帧数不足,二来角色不一致,三来只能做简单的摆头、转身动作。推特用户@Mega_Gorilla采用另一种方式来实现更高质量的3渲2效果,即利用AI绘画补足中间帧,另外在比较棘手的手部细节刻画上也有相应的Novel AI插件来克服。
![]()
与此同时,NIM也表现出了自己的隐忧,AI工具虽然会为AVG游戏圈带来更多不同领域的创作者,但工具本身的低门槛有可能带来大量粗糙的作品,它只不过是将原本用免费素材堆砌的劣质游戏换成了AI生成的内容罢了。
若是跳出AVG游戏领域,AI生成的图片可能会面临更多的问题,比如FPS里的原画,让AI设计一把拥有合理机械结构的武器并不容易,它只是用结果生成结果,它画一把武器长这样,是因为它“见过”的都长这样,它并不清楚武器的使用原理,不能理解武器怎样击发、怎样拿着舒服等,“指不定会出现一些使用突击步qiang却像用霰弹qiang一样拉着护木往外抛壳的笑话,当然这样可能会给设计师灵感也说不定。”又比如机甲游戏,游戏里的机甲一般都会与实体玩具联动,“机甲的设计须以现实中的工业水平能够生产,成本和良品率可控为前提,,这也是目前AI无法胜任的。”
AI生成的内容还存在一些共同的问题,如版权。NIM举了个可能发生的案例来说明:
“甲用AI生成的图片来游戏,火了。图片被乙盗用,制作出高度相似的仿品蹭热度和盈利。现在甲要告乙,但乙没有盗用甲原创的剧情,只盗用了甲用AI生成的美术素材,并用配音软件的同一声线进行配音。”
![]()
按理说,乙所做的事情就近似于如今的同人创作,但其有盈利目的,甚至能诱导玩家以为是同一角色。“由于甲没有PSD文件、草图,且没有当庭画出一张相同水平画作的能力,甲将难以为自己的角色、作品维权。”
当然,按照目前人们的诉求与AI技术的发展轨迹,版权、分辨率、稳定性、图层等问题未必没有解决之道。但AI生成内容所引发的远不只是技术层面或法律层面的问题,手工与机械、创造与复制、利用与依赖……这些围绕着技术所衍生的思辨仍然阻碍着人们全面拥抱AI的那一天,NIM在采访的结尾处也发出了类似的灵魂拷问:
“热爱创作的人,真的会稀罕那些简单点几下鼠标就能出来的东西吗?
至少对我来说,我用AI水的视频我是没有产生那种‘像自己孩子’的感觉。如果它被偷了,我是没法像倾注了心血的原创作品被偷了那样感到难过,只会觉得难绷,‘居然还有人会偷这种东西’……就像发现我随手发在QQ空间的街拍被盗图了一样。
我很难感觉用AI简单几步就生成的东西是我的,甚至我会感觉与其是我在使用AI创作,不如说是AI在使用我来筛选它画得好的作品,很多时候我就是一个打分的,这个6分这个3分这个十分。”
写在最后:
如今,离《未来地狱绘图》第一章发布已过去一个多月,科技界涌现出了更多AI生成内容的新工具或进展,根据图片生成图片,根据文字或图片生成短视频,根据文字或图片生成3D模型,自动上色,无缝纹理贴图,3D模型变形框架……
即便是文字生成图片技术,在一个月内也发生了诸多变化,科技公司比拼的不仅是如何用更短的时间输出更高质量的图片,同时还在更改算法让AI能够更好的“理解”需求,以及在“编辑图片”下更多功夫,如新发布的Stable diffusion 2.0,它允许用户对生成的图片进行“升级”,从原有的128x128分辨率提升至2048x2048甚至更高,同时能在不改变图片结构、主体姿势的情况下生成更多图像,谷歌推出的Dream booth则表现出了惊人的编辑功能,它仅需训练少量图片,就能让图片中的主体嵌入任何想要的场景之中,同时可以改变主体的动作、颜色乃至整张图片的风格……
![]()
AI生成内容的发展,似乎太快了,它每天都在刷新人们对其的认知,也让那些每个盯着其发展动态的人感到畏惧,当它被大规模地运用到实际的数字内容生产中时,将会发生什么样的情况?
从游戏开发的角度来说,AI绘画目前的能力显然无法满足实际的生产需求,无论是Midjourney还是Stable Diffusion,它们生成的概念画质量再高,想直接投入商业使用中依旧有难度,一方面,设计是多方沟通、协调的过程,另一方面,画得好并不意味着它是合理的、能够转换成实际的游戏资产(3D建模),AI绘画并不理解人类的绘图逻辑,很多细节都经不起推敲。
对于AI绘画的实际应用,更多地停留在了快速验证创意与方案可行性的阶段。
如36氪To B产业报道《从第一性原理出发,分析AI会如何改变视觉内容的创作和分发》一文中所揭示的,AI能够学习掌握配色、构图、光影、笔触等视觉知识,凭借着人类难以比拟的算力与数据库所搭建的高纬知识空间,迅速输出组合性的图片,它最大的价值在于“带来了一种全新的创意流通方式,在‘创意—图片—网站—图片—创意’之间建立了一个更短的‘创意—AI—创意’通路”。
![]()
画师可以利用AI绘画工具来找到新的构图方式或不同类型/风格组合可能性,策划或需求方可以利用AI绘画工具来表达自己想要的效果,进一步压低沟通成本。
实践是检验真理的唯一标准,AI绘画在数字内容生产领域是否是否具备不可忽视的作用,都得在战场上才能见真章,截至目前,海外已出现基于AI生成内容的商用游戏资产网站,Scenario,它允许用户“喂食”自己的历史作品来生成专有模型,或者是快速验证原型与高效量产,平台将于12月正式上线。
![]()
雷亚游戏则在近日发布的招聘需求中添加了AI美术设计师/沟通师岗位。
![]()
为避免错失机遇,一线游戏厂商甚至会研制专门的AI绘画工具或成立相关的研究小组,在产研一体的模式下推进AI绘画的落地使用。
无论如何,名为“AI生成内容”的风已经刮起,它将将掀起惊涛骇浪还是助力风帆航行尚且是个未知数,但它已然证实了一件事,AI技术想要解决的不仅是效率上的问题,它还想在人类自诩的创意领域分一杯羹。
机械生成的内容,是否真有创意可言?由AI制作的游戏,它会有趣吗?
原文:

从文本生成图片、图片生成图片,到文本生成3D模型、文本生成短视频,AI工具在海量网民的奇思妙想下,生成了诸多高质量或有趣的内容。在这场技术狂欢里,至少看到了这么几个趋向:
1.技术范式,基于库恩—佩蕾斯对于“范式”概念的阐释与演化,技术的演变伴随着价格结构的重大变化,从而引导经济行为者倾向于使用更强大的新投入品与新技术。之于AI绘画而言,它又可细分为——
技术的渐进式发展与跃迁,AI绘画在近几个月能突飞猛进式源于Diffusion扩散模型在图片生成领域的使用以及Stable Diffusion的开源,但这些跃迁无不建立在技术的长期研究基础上;
市场前景引发技术竞争,AI绘画技术的火热引起了全球巨头、科技公司的高度关注,谷歌、微软、Adobe等公司纷纷推出新的模型与实验性项目,并试图将该项技术整合到自家产品中, Stable Diffusion背后的创业公司融资一亿美元以进行更深入的研发;
AI绘画作为一种生产工具,将催生新的需求、岗位,或是改变现有的生产流程。

2.公众对绘画或艺术的再一次审视,如同杜尚用现成品艺术颠覆了人们对艺术的认知,计算机生成的图画引发了人们对艺术、人类创造力本质的新的讨论;
3.AI绘画对现有法律、社会认知的冲击,如AI的训练数据以及生成的图像是否对艺术家的作品构成侵权,AI生成图像是否有版权等。
在这些趋向与讨论中,新技术所引起的失业焦虑无疑是最具冲击性的话题之一,它是否会像部分网友所说的,取缔“低端”画手?
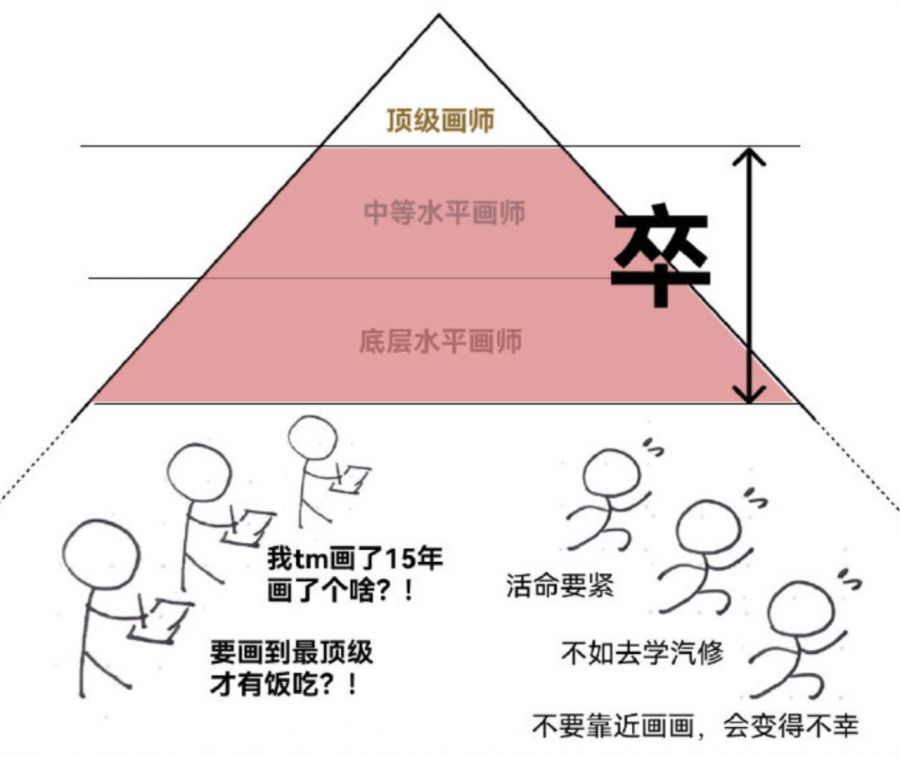
事实上,“取缔”与“低端”都不是贴切的说法,我们可以换个角度去思考AI绘画对美术从业者的潜在影响——将AI绘画产品的出图流程与人类作图的流程以及最终想要得到的成品放在同一个框架内考虑,得出哪些环节、成品可以被AI绘画优化甚至平替的。
基于这一思路,不难想象,约稿市场,可能会成为AI绘画蚕食的重灾区,又或者是那些仅需要数张插画的小说、有声作品等。
之于游戏产品,美术占比重、玩法固定的AVG游戏,同样岌岌可危。
这不,AI绘画热潮刚蔓延至国内的那段日子,就有个团队趁势做了个“由AI制作”的AVG游戏——《未来地狱绘图》。
《未来地狱绘图》
“由AI制作”,这一描述并不准确,《未来地狱绘图》的实质是用AI工具生成大部分游戏资产,如剧本、角色立绘、美术背景等,最后由人工完成素材的组合。

游戏由拔丝柠檬制作组制作,据官方在B站发布的介绍视频,游戏第一章的制作时长仅仅只有6个小时,游玩时长大概为10分钟左右,全程无对话选项,相当于一个视觉小说。

目前游戏可在Gamecreator网站在线游玩,更新至第二章节。

AVG游戏的制作门槛并不高,尤其是纯视觉小说类型的文字冒险游戏,它并不需要嵌入过多的游戏交互行为或游戏系统,市面上也存在着大量用于制作AVG游戏的引擎或平台,如吉里吉里、橙光。理论上,制作者仅需搞定剧本、美术(角色、场景、CG、特效等)、音乐(音乐、音效、配音等)三大模块,就能制作出一款能交互的AVG游戏。
而这三者,均在AI生成内容的范围内。
(1)剧本
《未来地狱绘图》使用的是彩云科技开发的人工智能小说续写工具彩云小梦。
用户在应用界面中输入故事开头、词语或主人公名称后,AI会自动续写下文,用户可以选择续写的风格,如“纯爱”、“玄幻”,也可上传文本训练出自己想要的模型,还能对故事的世界观进行编辑。每次续写时,AI会提供三种文本,不喜欢的话可以换一批。
该应用在去年曾火过一阵子,在B站上,以「AI续写」为标题的系列视频每一条都有着几十万的播放量,但这一热度并非基于AI续写的故事的质量产生的,纵览AI生成的文本,里头满是硬伤:故事逻辑性弱、语句毛病多,观众更多的是持着一种看乐子的心态,人类的围观与在AI基础上生成的脑洞远比故事本身更加有意思。
从彩云小梦在《未来地狱绘图》中的实际应用来看,行文硬伤依旧存在,语义重复的毛病并不少见:

但它至少做到了一件事,能够把事情讲清楚了——未来某一年,玩家所扮演的「员工」被AI所淘汰,试图反抗的“我”被教训了一顿后关进了看守所(第一章)。不知过了多久,“我”沦落街头,乞求能找到一份工作,并透露出自己此前的身份——能画出千万美元价值画作的画师。在小巷收废品时“我”遇到一名被遗弃的女仆机器人,“我”萌生了同病相怜的情愫,谁知,这竟是个圈套,性命攸关之际前同事打开了仓房的门(第二章)……
除了故事发生的前后逻辑能理得清外,AI创作的文本还有另一个比较令人意外的点,即每个角色的台词符合其人设。
通读下来,故事给人的感觉就是缺乏相应的铺垫或没有明确的发展方向,转折虽然有出人意料的效果但显得生硬。
(2)音乐
《未来地狱绘图》的AI音乐主要分为两大块,背景乐与角色配音,音效使用的是免费素材。

计算机领域对音乐的解析远比绘画要早得多,上个世纪50年代便有研究者尝试着用计算机随机生成弦乐。在神经网络技术的辅助下,人工智能已能熟练“掌握”音乐的基本原理并生成有一定表现力的音乐。

《未来地狱绘图》所使用的AIVA便是AI生成音乐领域的佼佼者之一,它允许玩家对生成的音乐进行编辑。不过,在《未来地狱绘图》里,AI生成的BGM存在感并不强,虽然算是一首能听的曲子,但并不能与当前的文本、画面完全贴合,产生1+1>2的效果。
相比AI生成的音乐,AI配音则要常见得多,公共广播、短视频中等随处可见,在营销号、电影解说中的使用更为泛滥,其中以微软AI语音云希、阿里云的艾飞最为普遍。
虽然这些AI配音已听不出太多机械音的痕迹,但它们只适用于解说等无需情感掺和的场景,在视觉小说这类强调故事性与角色的作品中,声音需要被赋予更多的情绪与灵魂。换言之,它需要更为复杂的语调、音长变化,于是便有了语音合成标注工具。
在《未来地狱绘图》所使用的声咖AI中,用户不仅能选择语音类型、朗读速度跟音量,还能对朗读文本逐字进行标注,通过停顿、强调、连读等方式实现发音的节奏变化。部分AI配音应用,如Uberduck,甚至允许用户自行上传音频素材训练出特定的模型,直接模糊同人与官方的界限。
不过,在《未来地狱绘图》的具体体验中,AI配音的表现其实很糙,机械感明显是其一,语调与发音人所处情景不吻合是其二——像“带走”、“给我进去”这些带有强迫性意味的词语尾音却拉得很长,既不符合机器人无情感的特性、也不符合人类的情感倾向。
相比AI配音,AI变声器是个更具效率的配音方案,如MockingBird、MoeGoe,后者在二次元领域较为常见,它收录了接近三千名动画角色的声音,可生成中文、日文、英文、韩语等多种语言,目前在日本的Vtuber行业有较高使用率。
(3)美术
回到本文、同时也是《未来地狱绘图》之所以会被做出来的契机上,AI绘画是三类AI生成内容中最具视觉冲击力(虽然它本身就是视觉产品)、成品最接近人类作品的,在媒体、互联网大规模曝光AI绘画技术以及Stable Diffusion开源之后,国内外涌现出了大量新AI绘画产品。
但总体而言,关注焦点依旧集中在DALL-E、Midjourney、Stable Diffusion上。
三者中,DALL-E算得上是奠基者。如今主流的文本生成图像(Text to Image,下文简称T2I)工具使用的模型均为CLIP+Diffusion,前者为计算机能够理解文本与图像之间的对应关系搭建起了桥梁,并网罗互联网中数十亿的图片作为自己的训练数据;后者则是利用“去噪点”的方式实现图像的精细度。DALL-E背后的开发团队Open AI于2021年1月开源了CLIP模型后,为TTI的跃进式发展提供了契机。
Midjourney的成名也许要归功于Colorado博览会上的伟大胜利,由其生成的作品力压人类艺术家拔得头筹,基于训练库的差异,Midjourney生成的图像更强调光影细节与美学观感。
Stable Diffusion后来居上,它秉承着完全开放的原则,过滤少、没有严格的版权保护机制(即使有,也能被轻易绕过或破解),输出的风格更为广泛,使用更为便捷,生成速度更快,且可得到社区支持。

当然,《未来地狱绘图》所使用的Novel AI也是AI绘画领域的佼佼者,尤其是在AI生成二次元画像方面。

运用到具体的AVG游戏制作中,AI所需要做的工作不能只停留于根据提示词生成图像,它至少还需要做到:
保证所有输出图片在风格上的统一性;
为同一角色绘制不同的动作与表情差分;
用于渲染氛围、展现故事张力的CG需要能够与上下文相一致,如角色样貌、服饰、场景等。
需要特别提醒的是,以上需求均建立在无人工改图、AI直出的情况下。
在《未来地狱绘图》中,制作者极力避免同一场景需要两张美术背景(如同一间屋子的不同部位)的情况,对于“场”做了明显的切割,至于角色的表情差分、动作差异,则一概摒除。
在CG如何与立绘保持统一这一关键需求上,游戏同样没能给出一个比较好的解决方案。

从《未来地狱绘图》的实际表现来看,无论是文本、音乐还是美术,AI生成的游戏内容都未能均不尽人意,也许单个(单张图片或片段性的文字)拎出来看成效还行,但全部拼贴在一起多少有些别扭,就像贫困的村庄里盖了个六七层的高楼,外体砌的砖墙五花八门,或古朴或时尚,或黄或绿,它缔造的不是奇观,而是单纯的不协调。
不过也别忘了,上个世纪的波普艺术便是用拼贴、剪切商品包装的方式成为一种新时尚的,也许AI生成的内容不是取缔现有的作品,而是成为新的一个品类呢?就像观众将AI小说当成乐子而非常规作品一样,媒介的差异造成了认知方式的差异。
但《未来地狱绘图》并不意味着就是AI在游戏创作上的极限,它只不过是个几个小时内鼓捣出来的实验性作品,理论上制作者可以用更好的AI工具、更细致的“调校”来生成更出色的作品,其结果便是——
与使用AI的初衷背道而驰,制作者需要投入更多的时间,甚至是金钱。

为了更好地理解《未来地狱绘图》以及AI生成内容在游戏制作上的实际使用,找上了游戏背后的开发团队,拔丝柠檬制作组。
一言难尽的AI生成技术
拔丝柠檬制作组的成立时间不足半年,出于了解新技术的态度,他们尝试着用AI工具鼓捣出了《未来地狱绘图》。
第一章花了大约6个小时的时间,因为是抱着做着玩的心态,所以对生成的素材并不细抠,能用即可。
第二章则花了两倍的时间,制作组想尝试用AI做更多的东西,比如CG——让AI生成同一角色的不同图片,制作人NIM表示,“即使是截取大量同角色的图片进行训练,让AI记住角色,生成的图片在细节上的差异也是不可避免的。”
用AI工具创作的《未来地狱绘图》只是拔丝柠檬制作组的试水作品,团队的工作重心在另一款AVG游戏《井域:喀洛之血》。

基于拥有用两套创作方式(人工与AI)来创作同一类型游戏的经历,拔丝柠檬制作组在“AI绘画是否会对游戏行业造成冲击”这一话题上有着更为真切的感受。
其初步结论是,目前用AI工具来创作AVG游戏并不见得更有效率。
比如文本,“彩云小梦生成的文本没有逻辑,如果想要达到能看的程度,免不了要人的参与”,相比纯试验性的第一章,第二章有了更多人工修改的痕迹,NIM没有直接更改AI的文风,但对生成的原句进行了大量剪辑与重复生成,以确保生成的文本没有过于偏离制作者的构思,但即便是采用这种低成本驯服AI的方式,最终还是花费了大量时间,相比人工撰写来说并不划算。

比如配音,AI直出的音频没有太多感情,需要进行精确的调参,但在AVG这种文本量动辄几十万起的游戏来说,调校过程中需要倾注的人力未必少于真人配音。
美术方面的问题也不少,第一是同质化明显,Novel AI生成的图相似性高,脸型重复,不适合用于原创的商业作品;第二是它无法满足专业需求,比如高分辨率的立绘,AI生成的图片放大后效果并不理想,又比如图片没有分图层,可供调整的余地不大;第三,CG难以保证角色的一致性;第四,生成的图有不少细节上的问题,这些都需要人工去修复。

但NIM并未完全否决AI的作用,以上结论建立在两个基本点上,一是目前AI生成工具的水准,二是使用者的用途与标准,如果仅是追求可读、可用的话,目前的AI完全能取代人工产出制作AVG游戏所需要的游戏资产。
对于NIM来说,在AVG游戏创作领域,AI生成工具有个明显的优势:
进一步降低制作门槛,让那些有想法或有故事想要表达的个体作者也能利用AI工具来创作游戏。B站上涌现的同人作品便是一个有力的证据。创作者们以VUP/Vtuber或者是一些现有IP为原型,将角色图片、配音“喂食”给AI,然后根据自身需求生成想要的内容,真正意义上让零美术基础的同学也能进而二创圈。
拔丝柠檬制作组还在B站上展示了一种利用AI绘画生成2D动画的技巧,先“喂食”图片生成可用的模型,然后用MMD制作3D动画并导出序列帧,最后用AI绘画将其转换成2D动画。
不过,这样生成的动画往往是由一张张重新绘制的图片合成的,一来帧数不足,二来角色不一致,三来只能做简单的摆头、转身动作。推特用户@Mega_Gorilla采用另一种方式来实现更高质量的3渲2效果,即利用AI绘画补足中间帧,另外在比较棘手的手部细节刻画上也有相应的Novel AI插件来克服。

与此同时,NIM也表现出了自己的隐忧,AI工具虽然会为AVG游戏圈带来更多不同领域的创作者,但工具本身的低门槛有可能带来大量粗糙的作品,它只不过是将原本用免费素材堆砌的劣质游戏换成了AI生成的内容罢了。
若是跳出AVG游戏领域,AI生成的图片可能会面临更多的问题,比如FPS里的原画,让AI设计一把拥有合理机械结构的武器并不容易,它只是用结果生成结果,它画一把武器长这样,是因为它“见过”的都长这样,它并不清楚武器的使用原理,不能理解武器怎样击发、怎样拿着舒服等,“指不定会出现一些使用突击步qiang却像用霰弹qiang一样拉着护木往外抛壳的笑话,当然这样可能会给设计师灵感也说不定。”又比如机甲游戏,游戏里的机甲一般都会与实体玩具联动,“机甲的设计须以现实中的工业水平能够生产,成本和良品率可控为前提,,这也是目前AI无法胜任的。”
AI生成的内容还存在一些共同的问题,如版权。NIM举了个可能发生的案例来说明:
“甲用AI生成的图片来游戏,火了。图片被乙盗用,制作出高度相似的仿品蹭热度和盈利。现在甲要告乙,但乙没有盗用甲原创的剧情,只盗用了甲用AI生成的美术素材,并用配音软件的同一声线进行配音。”

按理说,乙所做的事情就近似于如今的同人创作,但其有盈利目的,甚至能诱导玩家以为是同一角色。“由于甲没有PSD文件、草图,且没有当庭画出一张相同水平画作的能力,甲将难以为自己的角色、作品维权。”
当然,按照目前人们的诉求与AI技术的发展轨迹,版权、分辨率、稳定性、图层等问题未必没有解决之道。但AI生成内容所引发的远不只是技术层面或法律层面的问题,手工与机械、创造与复制、利用与依赖……这些围绕着技术所衍生的思辨仍然阻碍着人们全面拥抱AI的那一天,NIM在采访的结尾处也发出了类似的灵魂拷问:
“热爱创作的人,真的会稀罕那些简单点几下鼠标就能出来的东西吗?
至少对我来说,我用AI水的视频我是没有产生那种‘像自己孩子’的感觉。如果它被偷了,我是没法像倾注了心血的原创作品被偷了那样感到难过,只会觉得难绷,‘居然还有人会偷这种东西’……就像发现我随手发在QQ空间的街拍被盗图了一样。
我很难感觉用AI简单几步就生成的东西是我的,甚至我会感觉与其是我在使用AI创作,不如说是AI在使用我来筛选它画得好的作品,很多时候我就是一个打分的,这个6分这个3分这个十分。”
写在最后:
如今,离《未来地狱绘图》第一章发布已过去一个多月,科技界涌现出了更多AI生成内容的新工具或进展,根据图片生成图片,根据文字或图片生成短视频,根据文字或图片生成3D模型,自动上色,无缝纹理贴图,3D模型变形框架……
即便是文字生成图片技术,在一个月内也发生了诸多变化,科技公司比拼的不仅是如何用更短的时间输出更高质量的图片,同时还在更改算法让AI能够更好的“理解”需求,以及在“编辑图片”下更多功夫,如新发布的Stable diffusion 2.0,它允许用户对生成的图片进行“升级”,从原有的128x128分辨率提升至2048x2048甚至更高,同时能在不改变图片结构、主体姿势的情况下生成更多图像,谷歌推出的Dream booth则表现出了惊人的编辑功能,它仅需训练少量图片,就能让图片中的主体嵌入任何想要的场景之中,同时可以改变主体的动作、颜色乃至整张图片的风格……

AI生成内容的发展,似乎太快了,它每天都在刷新人们对其的认知,也让那些每个盯着其发展动态的人感到畏惧,当它被大规模地运用到实际的数字内容生产中时,将会发生什么样的情况?
从游戏开发的角度来说,AI绘画目前的能力显然无法满足实际的生产需求,无论是Midjourney还是Stable Diffusion,它们生成的概念画质量再高,想直接投入商业使用中依旧有难度,一方面,设计是多方沟通、协调的过程,另一方面,画得好并不意味着它是合理的、能够转换成实际的游戏资产(3D建模),AI绘画并不理解人类的绘图逻辑,很多细节都经不起推敲。
对于AI绘画的实际应用,更多地停留在了快速验证创意与方案可行性的阶段。
如36氪To B产业报道《从第一性原理出发,分析AI会如何改变视觉内容的创作和分发》一文中所揭示的,AI能够学习掌握配色、构图、光影、笔触等视觉知识,凭借着人类难以比拟的算力与数据库所搭建的高纬知识空间,迅速输出组合性的图片,它最大的价值在于“带来了一种全新的创意流通方式,在‘创意—图片—网站—图片—创意’之间建立了一个更短的‘创意—AI—创意’通路”。
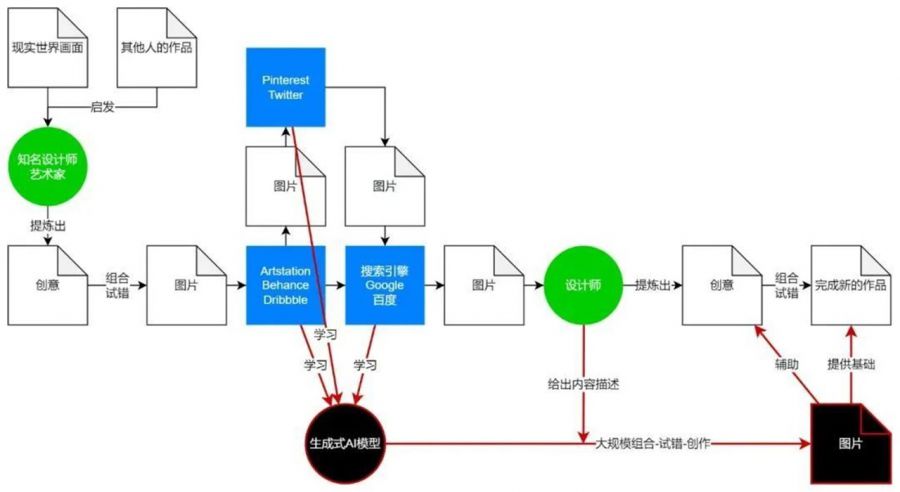
画师可以利用AI绘画工具来找到新的构图方式或不同类型/风格组合可能性,策划或需求方可以利用AI绘画工具来表达自己想要的效果,进一步压低沟通成本。
实践是检验真理的唯一标准,AI绘画在数字内容生产领域是否是否具备不可忽视的作用,都得在战场上才能见真章,截至目前,海外已出现基于AI生成内容的商用游戏资产网站,Scenario,它允许用户“喂食”自己的历史作品来生成专有模型,或者是快速验证原型与高效量产,平台将于12月正式上线。

雷亚游戏则在近日发布的招聘需求中添加了AI美术设计师/沟通师岗位。
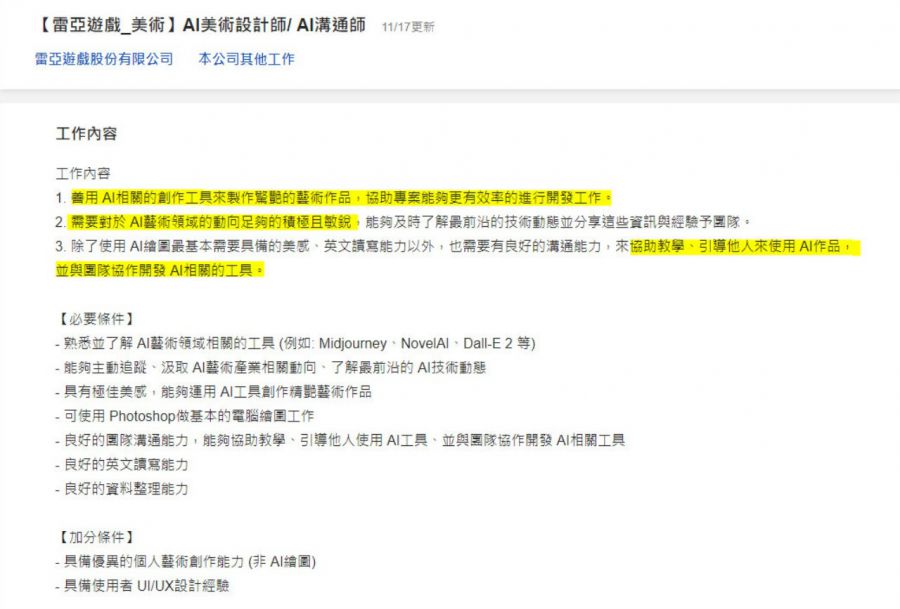
为避免错失机遇,一线游戏厂商甚至会研制专门的AI绘画工具或成立相关的研究小组,在产研一体的模式下推进AI绘画的落地使用。
无论如何,名为“AI生成内容”的风已经刮起,它将将掀起惊涛骇浪还是助力风帆航行尚且是个未知数,但它已然证实了一件事,AI技术想要解决的不仅是效率上的问题,它还想在人类自诩的创意领域分一杯羹。
机械生成的内容,是否真有创意可言?由AI制作的游戏,它会有趣吗?
原文:
目录
推荐阅读
5 条评论
你 请文明发言哦~
-

相应的Novel AI插件来克服。 与此同时,NIM也表现出了自己的隐忧,AI工具虽然会为AVG游戏圈带来更多不同领域的创作者,但工具本身的低门槛有可能带来大量粗糙的作品,它只
-

作品,它只不过是将原本用免费素材堆砌的劣质游戏换成了AI生成的内容罢了。 若是跳出AVG游戏领域,AI生成的图片可能会面临更多的问题,比如FPS里的原画,让AI设计一把拥有合理机械结构的武器并不容易,它只是用结果生成结果,它画一把武器长这样,是因为它“见过”的都长这样,它并不
-

如文本,“彩云小梦生成的文本没有逻辑,如果想要达到能看的程度,免不了要人的参与”,相比纯试验性的第一章,第二章有了更多人工修改的痕迹,NIM没有直接更改AI的文风,但对生成的原句进行了大量剪辑与重复生成,以确保生成的文本没有过于偏离制作者的构思,但即便是采用这种低成本
-

图片在细节上的差异也是不可避免的。” 用AI工具创作的《未来地狱绘图》只是拔丝柠檬制作组的试水作品,团队的工作重心在另一款AVG游戏《井域:喀洛之血》。 基于拥有用两套创作方式(人工与AI)来创作同一类型游戏的经历,拔丝柠檬制作组在“AI绘画是否会对游戏行业造成冲击”这一话题上有着更为真切